[語料庫模型] 09-回饋機制
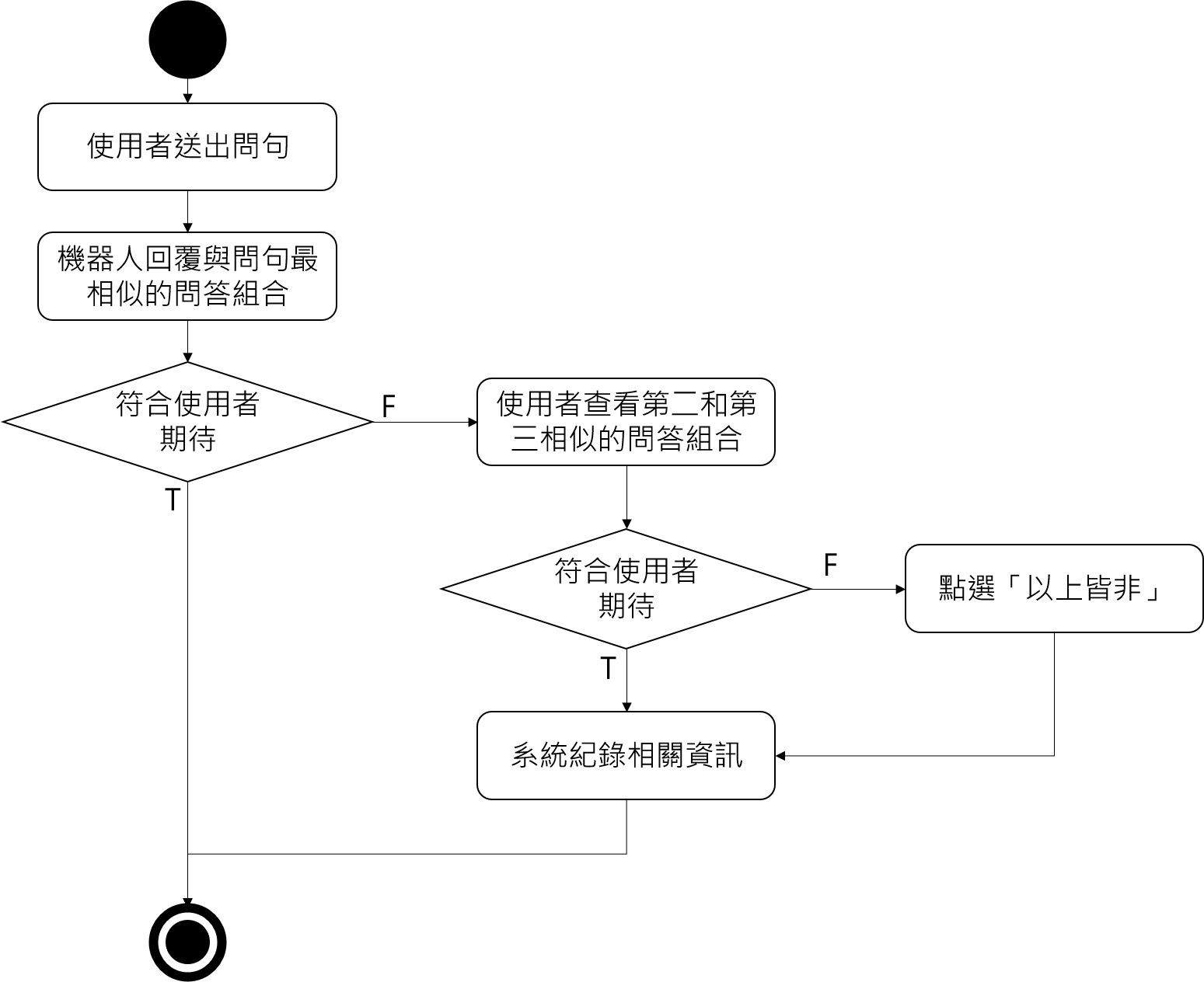
聊天機器人雖有問答集可以回覆大部分常見問題,但難免會有疏漏。因此本研究亦設計回饋機制,若使用者發現機器人的回覆內容不符合想預期,可以直接查看與問句第二和第三相似的問答組合,或是點選「以上皆非」選項,兩種方式系統都會自動記錄相關資訊。後續我們便可整理蒐集到的組合,持續優化聊天機器人與擴增問答集。
「[語料庫模型] 07-程式碼: 餘弦相似性」這篇的程式碼會回傳相似度最高的 3 個問答組合。
回饋紀錄使用與問答集相似的 CSV 格式儲存,方便整理後移植到資料集中。
- 回饋紀錄的 log
連結: https://gitlab.com/graduate_lab415/nlp/-/blob/master/output/adjustments.bk.csv

- 問答集(語料庫)
連結: https://gitlab.com/graduate_lab415/nlp/-/blob/master/docs/fixed_file_1622789141_remove_duplicate_labeled_renumber.csv
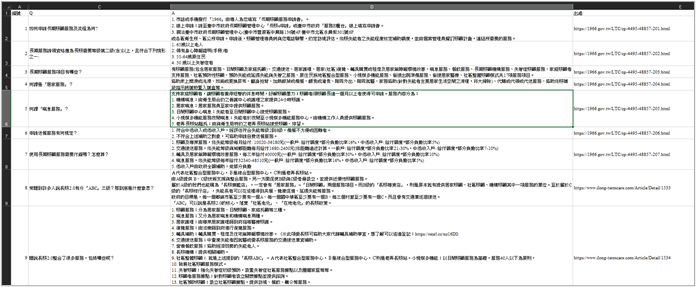
比較不同的是,回饋紀錄的 Q 欄位代表的是使用者輸入的語句,A 欄位則會根據使用者的選擇而有不同,主要分為兩種情況。
- 情況一,點選其他相符的選項
使用者輸入「申請喘息服務」,而機器人一開始回覆的問答組合不符預期,所以使用者點選查看第三相符的問答組合「總則(給付八)_獨居長輩是否能使用喘息服務」,因此可以判斷「使用者輸入的語句」與「第三相符問答組合的答案」較相符,並將此新的問答組合儲存於回饋紀錄中。
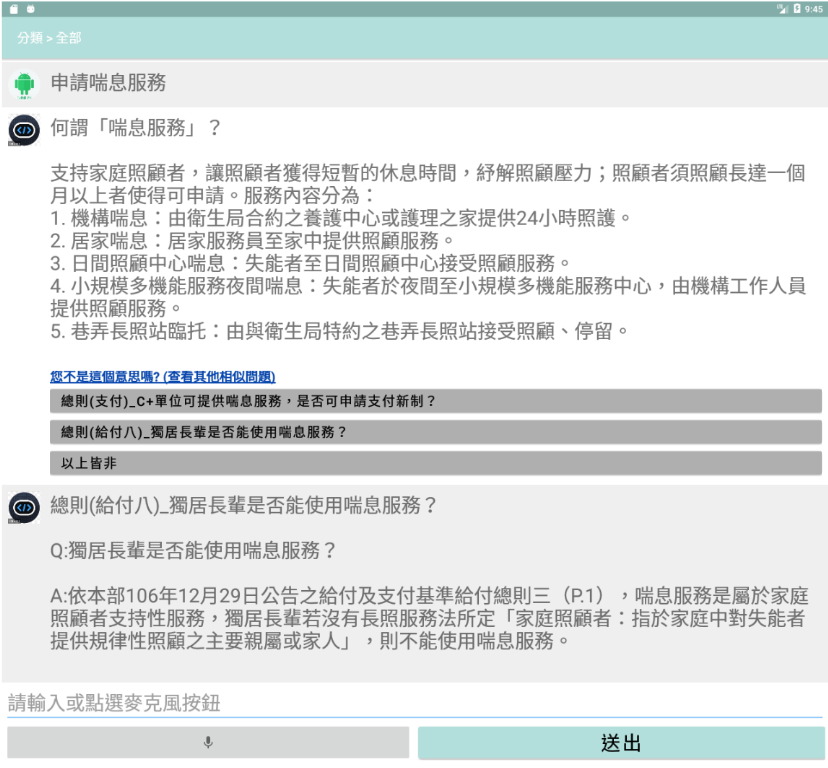
- 情況二,點選「以上皆非」
使用者輸入「外籍看護來自哪一國」,而機器人回覆的內容都不符合使用者期待,所以他選擇「以上皆非」,代表此問題對我們問答集來說是新問題,因此回饋紀錄就會記錄一筆新的問答組合。
程式碼
程式碼: https://gitlab.com/graduate_lab415/nlp/-/blob/master/add_adjustment.py
這部分的程式碼,是為了讓 API 可以將回饋紀錄寫進檔案
接收參數
1 | param = sys.argv |
可以接收像是這樣的參數
1 | python3 add_adjustment.py "申請喘息服務" 359 0 |
判斷是否為新問題
新問題是指使用者選了「以上皆非」,也就是說使用者認為他的問句和我們提供的都不相似,我們把這種狀況認為是新問題。
1 | if qa_id == "-1": |
result 是用來記錄狀況,印出最後的 JSON 檔案的。remark 就是備註,若是新問題,備註就會記錄 “New Question”;反之,則紀錄使用者認為更貼近問題。answer 是針對使用者的問句,若是新問題,就留空,待後續維護人員評估;反之,使用編號 359 查出問答組合,並把答案的部分存到 answer。

將記錄寫入檔案
1 | file_exist = os.path.isfile("/home/yr/PycharmProjects/nlp/output/adjustments.csv") |
首先檢查 adjustments.csv 檔案是否存在,若不存在,就開個新檔,並把欄位名稱寫進去。
檔案已存在,就把紀錄直接寫到檔案的最後一筆。
w: 開新檔 & 寫入
a+: 用附加方式打開(資料會加在檔案最後,不會把前面的內容洗掉) & 可讀寫
檢查寫檔是否成功
1 | success = writer.writerow(new_row) |
這部分可能沒寫很好,未來可以再修正寫法。
主要是想以 new_row 的長度來決定是否有新增成功,判斷的時候又遇到一些問題,不太了解為何 len(['', '', '', '', '']) 的結果是 6,就先將錯就錯,若是長度有大於 5 個空字串的 list,就算他成功吧。
印出 JSON
1 | print(json.dumps(result, ensure_ascii=False)) |
印出剛剛準備的 result,回饋機制的 API 就完成了!
1 | { |