嗨,昨天語料庫模型建好了,下一步要如何使用呢? 我們要如何比對輸入的句子與語料庫中的哪一句最相似呢?
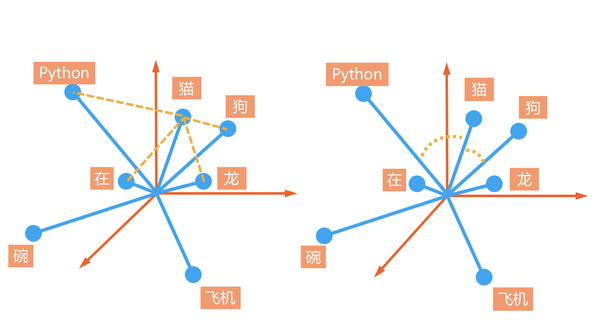
相似度計算方式 計算兩個點之間存在的差異大小,主要有兩種方式,歐式距離與餘弦相似度。歐氏距離與餘弦相似度的比較
歐式距離 主要計算空間中點與點之間的距離。
餘弦相似度 主要計算向量間的夾角大小。
而餘弦相似度的公式由「內積公式」推導而來。
餘弦相似度無關乎向量大小,重點是向量之間的方向。
方向一致時餘弦值為 1
直角時餘弦相似度的值為 0
方向相反時餘弦值為 -1
詞向量 此段參考 机器是这样理解语言 - 词向量 | 莫煩Python
大部分時候,我們注重的不一定是點與點之間的距離,更重要的是兩個向量的方向是否接近。這時候,餘弦相似度就比歐式距離適合。
程式碼 莫煩 Python 的程式碼: https://github.com/MorvanZhou/NLP-Tutorials https://gitlab.com/graduate_lab415/nlp/-/blob/master/main.py
執行 1 2 3 4 5 6 7 8 9 10 11 12 """test""" q = sys.argv[1 ] if CUT_METHOD == "ckip" : tmp_q = [q] q = tmp_q scores = docs_score(q) d_ids = scores.argsort()[-3 :][::-1 ] if LOG: print ("\n[{}] top 3 docs for '{}':\n{}" .format (CUT_METHOD, (q if CUT_METHOD != "ckip" else q[0 ]), [docs[i] for i in d_ids]))
第一句 q 是讀入要比較的句子,sys.argv[1] 就是用來讀取執行程式碼時輸入的參數,過幾天的文章會寫到。我如果還記得,再回來補連結…docs_score(q) 計算 q 和其他所有句子的餘弦相似性。
Python List 操作方式
1 2 3 4 5 a = [1, 2, 3, 4, 5] a[::-1] #[::-1] 是倒置,輸出: [5, 4, 3, 2, 1] a[-3] #[-3] 是倒數第 3 個,輸出: 3 a[-3:] #[-3:] 是從倒數第三個到最後一個,輸出: [3, 4, 5] a[-3:][::-1] #輸出: [5, 4, 3]
計算分數(餘弦相似度) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 def docs_score (query, len_norm=False ): """斷詞""" if CUT_METHOD == "jieba" : q_words = CutSentence.cut_jeiba(re.sub('[??()()「」,,、。::_“”→]' , ' ' , query), log=LOG) elif CUT_METHOD == "ckip" : q_words = CutSentence.cut_ckip(query, log=LOG) temp_arr = np.array(q_words) temp_arr = temp_arr.reshape(len (q_words[0 ])) q_words = temp_arr else : q_words = query.replace("," , "" ).split(" " ) """label""" if LABEL: q_words = add_label(q_words) """add unknown words""" unknown_v = 0 for v in set (q_words): if v not in v2i: v2i[v] = len (v2i) i2v[len (v2i) - 1 ] = v unknown_v += 1 if unknown_v > 0 : _idf = np.concatenate((idf, np.zeros((unknown_v, 1 ), dtype=np.float )), axis=0 ) _tf_idf = np.concatenate((tf_idf, np.zeros((unknown_v, tf_idf.shape[1 ]), dtype=np.float )), axis=0 ) else : _idf, _tf_idf = idf, tf_idf counter = Counter(q_words) q_tf = np.zeros((len (_idf), 1 ), dtype=np.float ) for v in counter.keys(): q_tf[v2i[v], 0 ] = counter[v] q_vec = q_tf * _idf q_scores = cosine_similarity(q_vec, _tf_idf) if len_norm: len_docs = [len (d) for d in docs_words] q_scores = q_scores / np.array(len_docs) return q_scores
一個新拿到的 q (這個 function 中叫 query),進行比較前,也要經過段詞、加 label,再檢查 query 有沒有新的詞,有的話就要加到 v2i 和 i2v 裡面。將 query 轉換成向量 q_vec 後才能算相似性唷。
最後 q_scores = cosine_similarity(q_vec, _tf_idf) 計算 query 與每個句子的相似性。
結語 終於寫完了,這篇應該本系列是最難的一篇了,我早上還先複習了數學呢。
參考資料