[語料庫模型] 05-實體對應
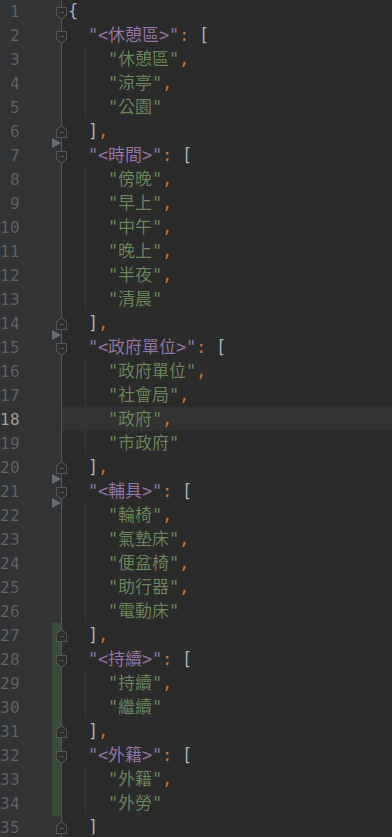
在語句中常會出現概念相似的詞,包括某類物品、地名、時間…等。例如,輪椅、拐杖、助行器、電動床都屬於輔具實體;早上、中午、下午、傍晚屬於時間實體。將這些詞語對應到所屬的類別,可以使程式判斷使用者意圖時更貼近。
本研究使用 JSON 檔案紀錄詞語及其實體,並在程式完成斷詞後,將詞語一一對應到實體。需要增加實體時,可以直接修改檔案。
實體對應設定檔: https://gitlab.com/graduate_lab415/nlp/-/blob/master/docs/entities_config.json
程式講解
完整程式在這邊: https://gitlab.com/graduate_lab415/nlp/-/blob/master/main.py
設定是否加標籤
首先我在最上方的設計了一個變數,控制是否要為問句加上標籤。
1 | """ |
判斷是否加標籤
接著程式會判斷本次製作模型,是否需要加標籤。若是,執行下方程式碼;若否跳過此段不執行。
1 | """use labeled or unlabeled""" |
open("檔案位址", "讀取模式") 是開啟前面我們設計好的設定檔。因為剛讀入的設定檔是純文字,因此接著使用 json.load() 將它轉成 json 格式。接下來使用迴圈為每一句問句加上標籤,並存入 docs_words_labeled 的 list 之中。
加標籤函式
主要負責為句子加上標籤。
1 | def add_label(doc, |
先講參數部分
doc: 要加標籤的句子label_config: 標籤的設定檔。這邊是 Python 的一個特別的寫法,當沒有傳入參數時,直接使用預設值。
昨天我們先斷過詞了,所以接下是把每詞拿出來和設定檔比對若有符合,就把詞的部分改成標籤。像是這樣:
1 | Before: ["請問", "哪裡", "可以", "借", "輪椅"] |
如此一來,不管今天使用者想借的是什麼輔具,都可以對應到問題囉!