[緒論] 長照小幫手的背景與動機
大家好,其實這個長照小幫手是我的論文題目,所以這系列的多文章,會有一大部分來自簡化的論文內容,再加上一些沒有收錄進論文的研究心得。
聊天機器人整套系統都是我一個人開發的,所以這系列文章應該會分為 Zenbo、爬蟲、TF-IDF、API、Android APP 幾個部分來介紹,之後會有一篇介紹整體系統架構。
背景
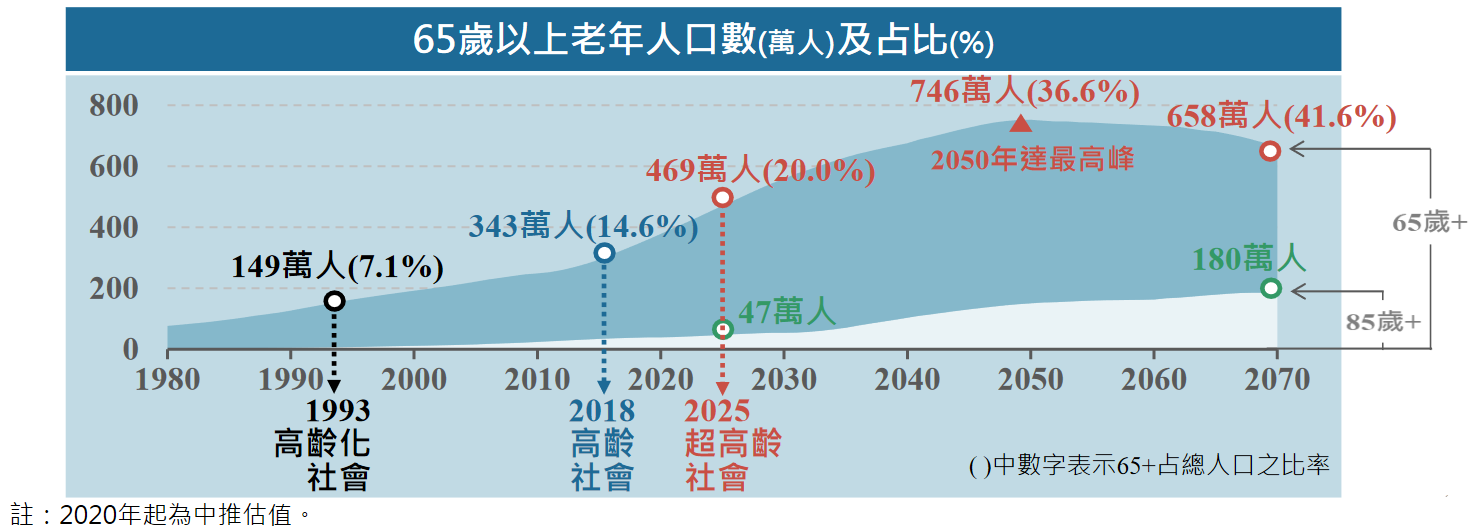
台灣人口老化問題越來越嚴重,預估在 2025 年將進入「超高齡社會」(國家發展委員會,2020)。試著想像全台灣每五人就有一人是老人,比例真的很高,這也造成患有慢性病或失能等長者的照顧需求跟著提升。
- 圖片取自(中華民國人口推估(2020 至2070 年)簡報, 2020)
動機
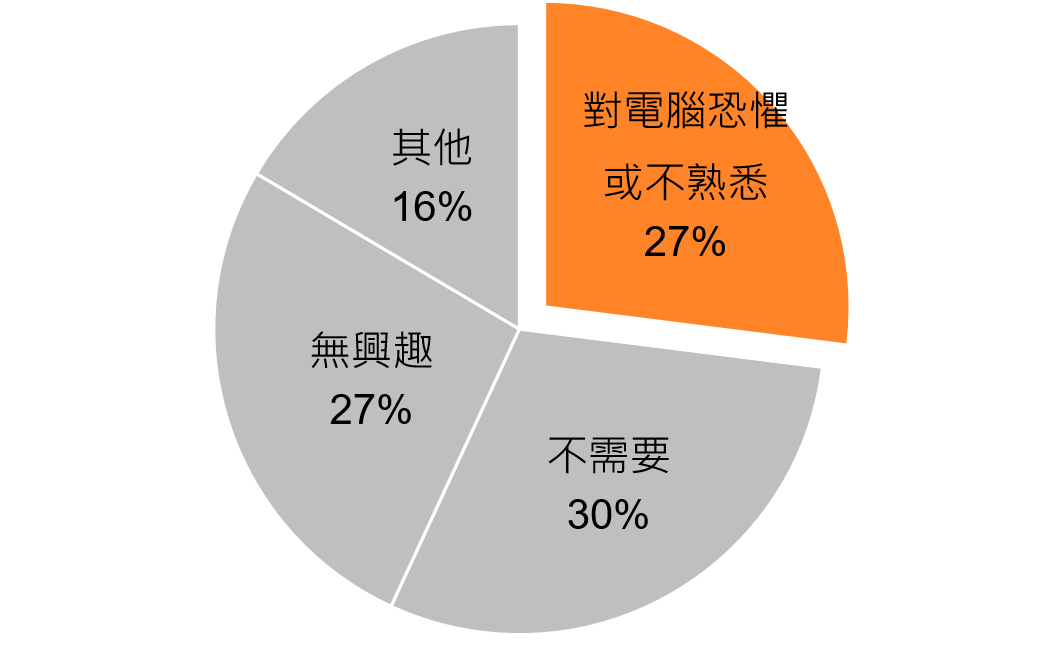
政府提供了很多長照資源,但除了電視和鄰里長的宣傳,長者比較難有管道了解其他適合自己的長照資源。根據統計(財團法人台灣網路資訊中心,2019),台灣有10.8%的民眾未使用網路,且以60歲以上的年齡層居多,其中「對電腦恐懼或不熟悉」的理由就佔了27%。
- 民眾未使用網路的原因,數據整理自 2019 台灣網路報告(財團法人台灣網路資訊中心,2019)
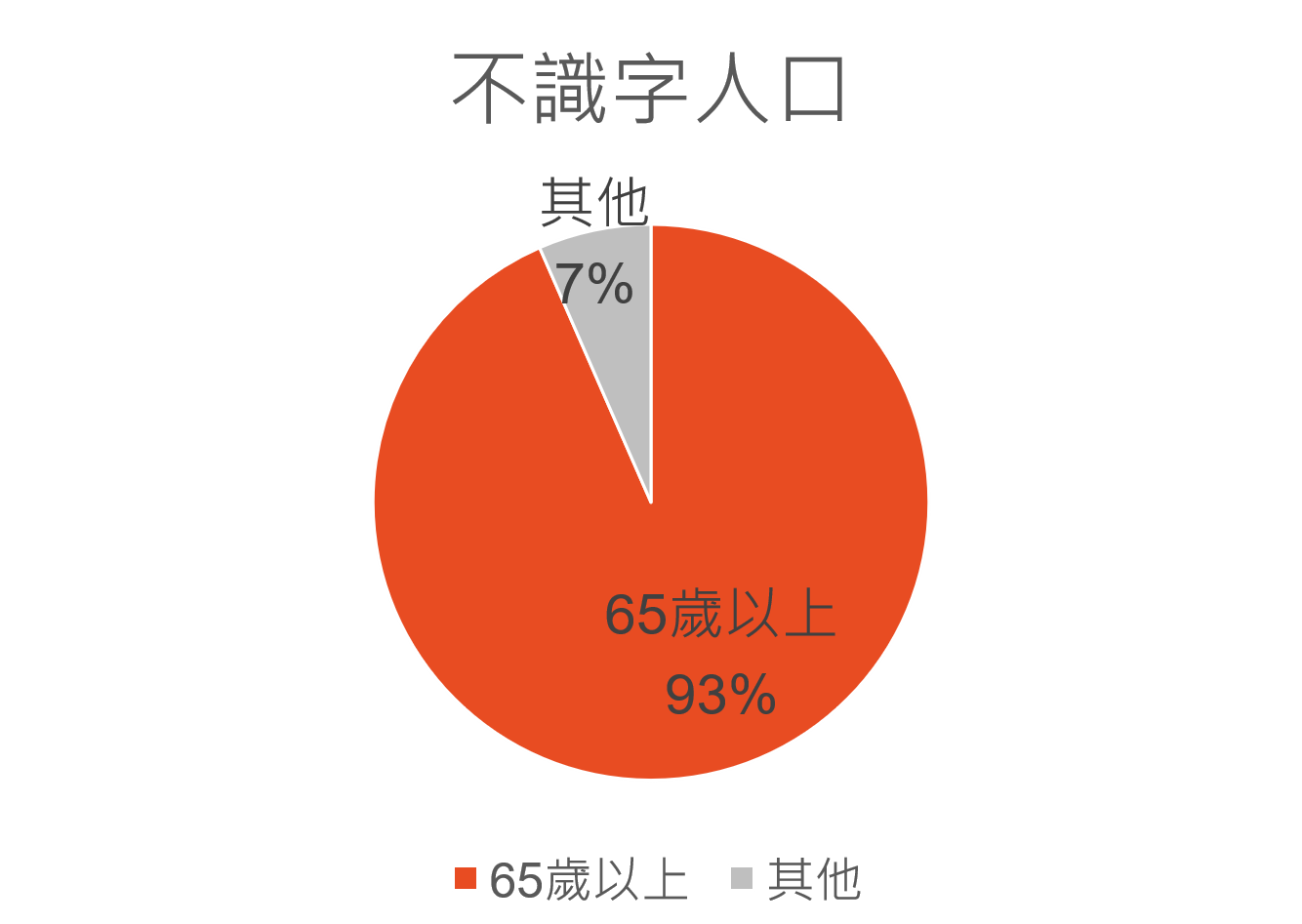
再加上,內政部統計(內政部統計處,2021),民國 109 年全國不識字的人口還有大概 20 萬,其中有 93% 是 65 歲以上長者。而不識字的老年人口約占全部老年人口的 5%。
- 不識字人口,數據來自於內政部統計處
當前的問題
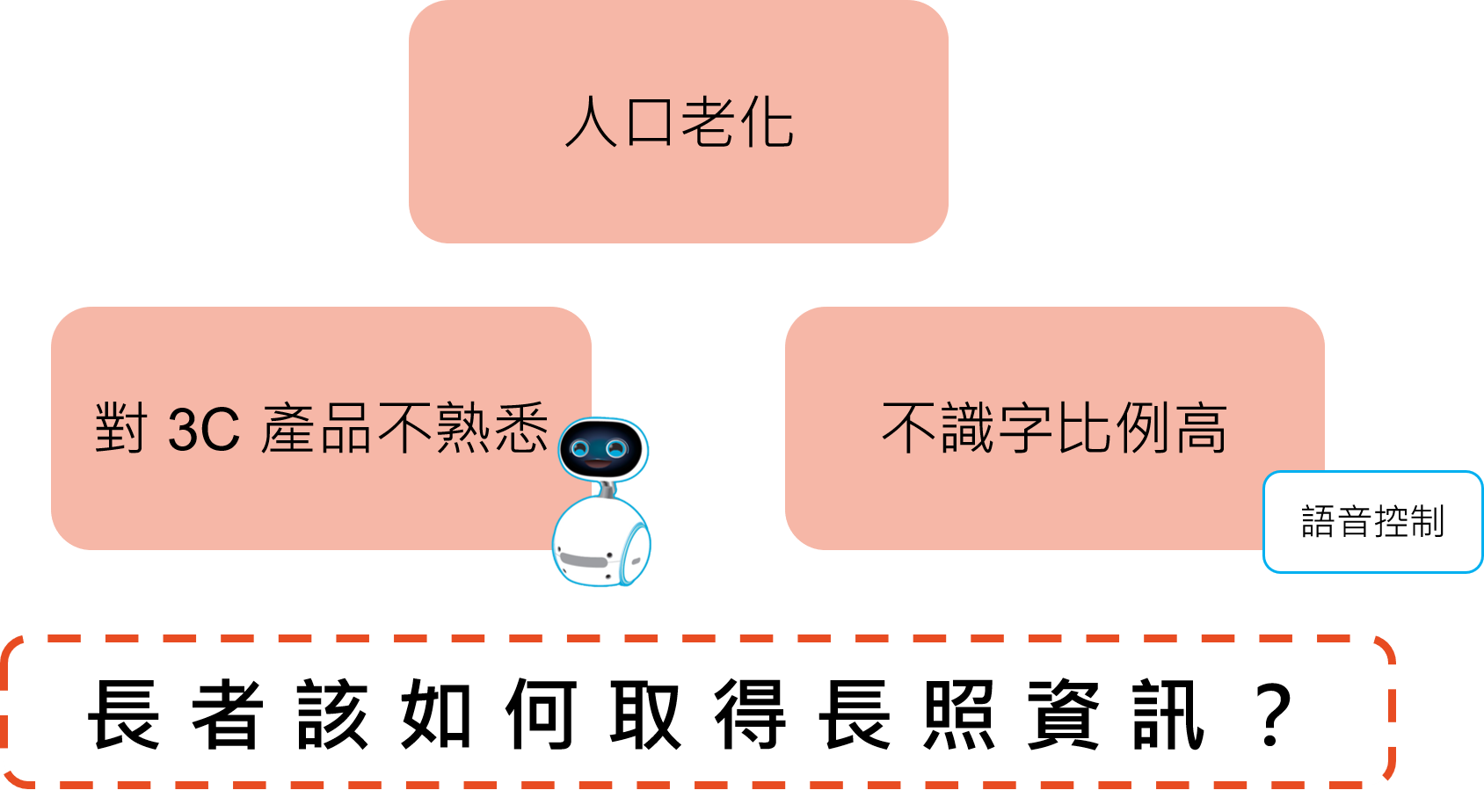
我們有人口老化的問題,還有長者「對 3C 產品不熟悉」和「不識字比例高」,那我們該如何讓長者有機會了解政府提供的長照服務呢?
因此我們決定選擇華碩推出的Zenbo機器人。Zenbo 可愛的外型與簡易口令的操作方式,可以降低長者對電子產品的恐懼。還有這次設計的聊天機器人特別加入語音控制功能,可以用語音輸入問句,機器人也會用語音回答。所以就算是不識字的長輩也能操作。
同時,我們也找到另一份文獻(Mary C. Gilly & Valarie A. Zeithaml, 1985),他說老人傳統上被認為是比較抗拒改變的,但是當技術滿足他們的需求,並得到有效的溝通時,老年消費者確實願意改變。
走錯路的過程
研究的過程中難免會寫到一半發現不合用的狀況嘛,所以整理一下不同技術的優缺,和我最後使用某個技術的原因。在後續的文章中可能會有比較詳細的說明😃。
語音輸入與輸出 - Zenbo SDK vs Android Library
一開始我使用的是 Zenbo SDK,為了讓 Zenbo 的語音、用字更符合台灣用法,華碩自行建立語音資料庫。但使用的過程中發現,Zenbo SDK 好像不太能處理破音字問題,加上念句子會跳字(某些字跳過沒唸)。所以我後來改用 Android 內建的 RecognizerIntent 和 TextToSpeech,雖然在句子比較複雜的時候,還是有機會唸錯破音字,但機率上好很多。
語料模型 - DDE vs DialogFlow vs TF-IDF
最一開始是使用 ASUS 提供的 DDE 工具,優點是安裝到 Zenob 比較方便,不須外另外串接 API。缺點是每個句子的 rule 都要手動建立,如果 rule 太寬鬆,input 可能會同時符合多個 rule,但是太嚴格,又可能 input 比對不到任何句子。
再來考慮 Engati、DialogFlow 這類可以串接常用通訊軟體的平台,但是發現每個句子都還是要手動建立,我有快 500 個句子,會死掉吧。但是 DialogFlow 提供模糊比對,算是解決了 DDE rule 規劃的問題。如果你的句子不多,且又有條件判斷,那 DialogFlow 還是可以推,只是它不符合我這裡的使用。
最後就剩自己建模型的路囉🙃,我的模型最後是選用 TF-IDF,主要程式碼是參考 MorvanZhou/NLP-Tutorials,再經過自己的修改。主要是因為研究 NLP 的時候發現主要都是關於句子生成的主題比較多,但我要的是比對句子的相似性,所以 TF-IDF 比較符合我的需求。
斷字系統 - Jieba vs CKIP
Jieba 來自中國,CKIP 來自中研院,在使用內建斷詞字典的狀況下,有一些台灣的專有名詞或簡稱,CKIP 表現的比 Jieba 比較好。
參考資料
- 國家發展委員會(2020)。中華民國人口推估(2020 至2070 年)報告。臺北:國家發展委員會。檢自:https://pop-proj.ndc.gov.tw/upload/download/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E4%BA%BA%E5%8F%A3%E6%8E%A8%E4%BC%B0(2020%E8%87%B32070%E5%B9%B4)%E5%A0%B1%E5%91%8A.pdf。
- 國家發展委員會(2020)。中華民國人口推估(2020 至 2070 年)簡報。檢自:https://pop-proj.ndc.gov.tw/upload/download/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E4%BA%BA%E5%8F%A3%E6%8E%A8%E4%BC%B0(2020%E8%87%B32070%E5%B9%B4)%E7%B0%A1%E5%A0%B1.pdf。
- 財團法人台灣網路資訊中心(2019)。2019 台灣網路報告。財團法人台灣網路資訊中心。檢自:https://report.twnic.tw/2019/。
- Mary C. Gilly & Valarie A. Zeithaml. (1985). The Elderly Consumer and Adoption of Technologies. Journal of Consumer Research, 12(3), 353-357. DOI:10.1086/208521
- 內政部統計處(2021)。 15 歲以上教育程度─按區域別、年齡別分. 內政統計查詢網。檢
自:https://statis.moi.gov.tw/micst/stmain.jsp?sys=100。